New · Should you run your own AI?
Local AI Decision Kit
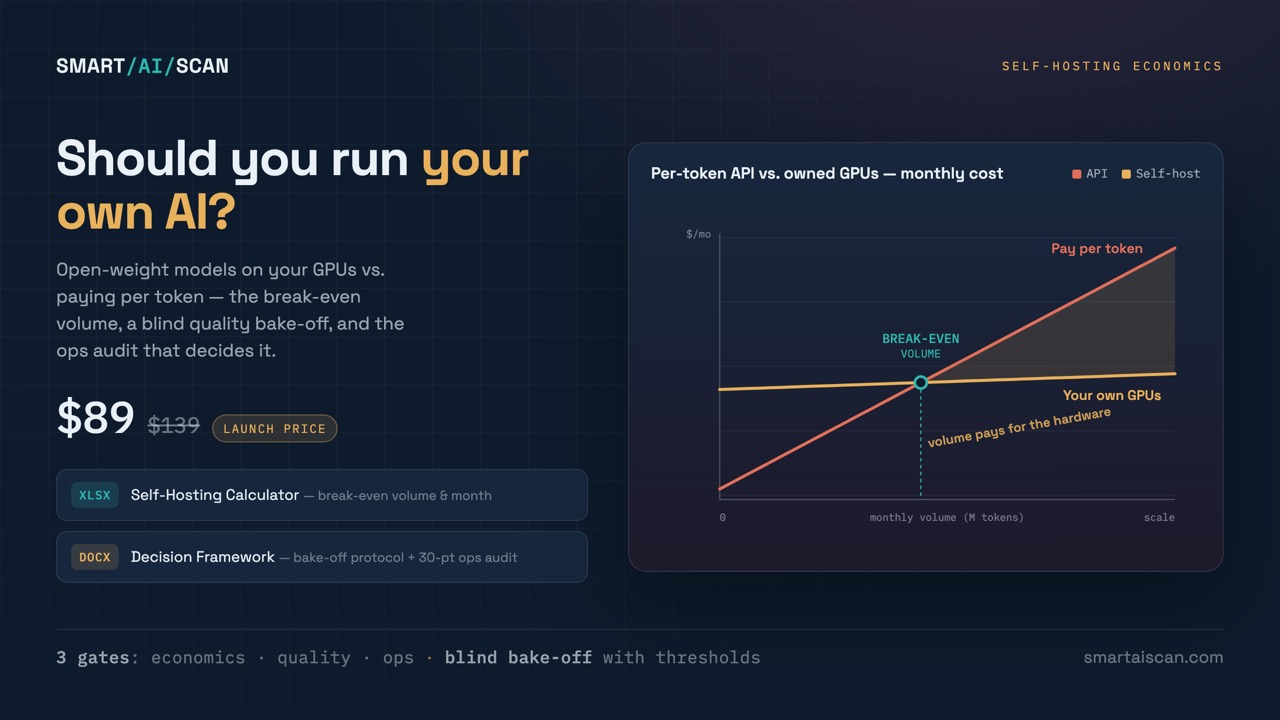
Open-weight models on your GPUs vs. paying per token. Break-even volume and month, a blind quality bake-off protocol, and the 30-point ops audit that kills GPU impulse buys.
$89$139
Get the kit — instant download
XLSX + DOCX · instant download